AWS上で動くWEBサービスに問題が発生した場合の、調査方法について解説しました。調査の必要性に迫られた場合は、「1.複数のデータを時系列に並べる」「2.時系列データから事実を把握」「3.原因を推測」「4.全体像を描く」という流れを意識して対応してみましょう。

調査とは
適切な再発防止策の検討をする場合に、原因調査は必須の要素になります。調査は大きくわけて2種類のものがあります。
①問題や事象から発生原因を特定する
②原因から影響を調べる
■問題や事象から発生原因を特定する
問題には必ず原因があります。取り急ぎの一次対応では復旧を優先しましたが、それだけでは同様の問題が再発してしまいます。落ち着いたタイミングで、根本原因の調査をおこなう必要があります。
■原因から影響を調べる
目に見える事象とは全く関係のない部分で、影響が発生している可能性があります。原因が特定できると、影響の調査が可能です。
調査対象

調査対象
調査はどのように行えばいいのでしょうか?主に4つの観点から調査していきます。
■事象
何がいつ発生したのかを把握します。検知したアラートの種類や、ユーザーから報告があった内容、その時のインフラの状態などの情報を整理します。
■影響
それによって発生した影響についても把握し、できる限り整理していきます。
■ログ
問題解決後に調査を行う場合は、環境に残された証跡を確認することになります。代表的なものがログです。AWS上で取得可能なログはもちろん、OSやミドルウェアが出力するようなインスタンス上のログ等を確認します。
■稼働データ
メモリやCPUなどのメトリクス情報も有用な手掛かりです。
調査の流れ

調査の流れ
調査方法の参考になるように、代表的な調査の流れを1つご紹介します。
1.複数のデータを時系列に並べる
2.時系列データから事実を把握する
3.原因を推測する
4.全体像を描く
詳細は以降の調査例で解説します。
一つの部分に注目し続けていても、原因の特定ができないことは多くあります。複数の事象を組み合わせて、全体像を組み立てていくことが重要です。
お客様で原因調査を行うポイント

お客様で原因調査をする場合のポイント
お客様で原因調査を行うポイントです。
原因特定までの時間や精度は、エンジニアの技術的スキルや経験に大きく左右されます。
若手エンジニア2日かかって解決できなかったことが、ベテランエンジニアが調査したら30分で解決した。ということも多く起こります。
そのため、高い技術スキルをもったエンジニアの確保が重要になります。また、技術要素は日々増え続けています。エンジニアに対する継続的な教育や経験を積めるように考慮しましょう。
調査事例:応答遅延の原因特定

調査事例
調査の流れを理解するために、具体的な調査事例をご紹介します
ECサイトを運営中のA社様の事例です。重要なタイミングで応答遅延が発生したので、原因特定をすることになりました。
既に応答遅延の事象は解消済みなので、アラート内容と各種ログを元に調査を進めていきます。
1.複数のデータを時系列に並べる
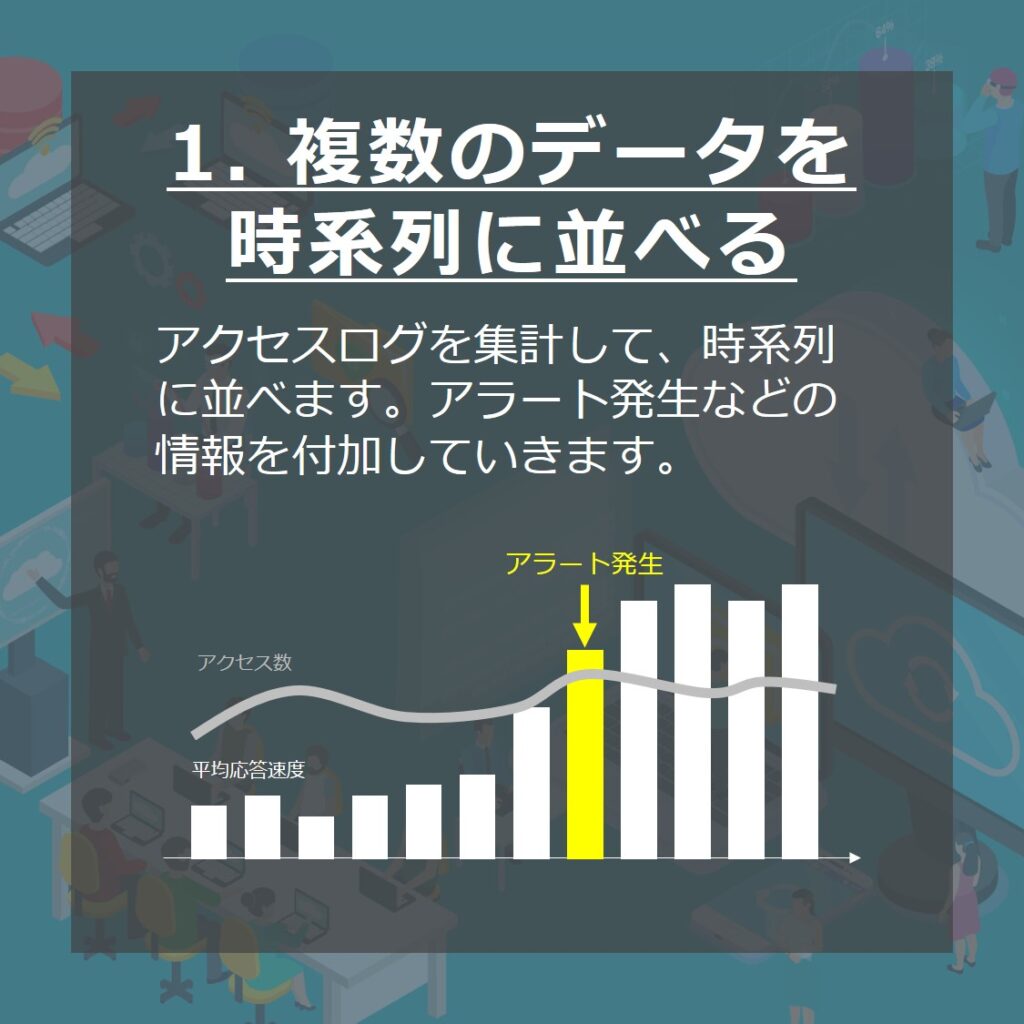
1.複数のデータを時系列に並べる
まずは、複数残されているデータを時系列に並べていきます。
応答遅延が発生しているということで、WEBサーバーのアクセスログを活用します。平均応答速度とアクセス数の情報が役立ちそうです。LinuxコマンドやExcelなどを活用し、アクセス数と平均応答速度を時系列でグラフ化します。
並べ終わったら、アラート発生などの情報を追加していきます。平均応答速度やアクセス数の時系列推移に情報を重ねることで、徐々に全体像をはっきりさせることが可能です。
必要に応じて、対象のURLやステータスコード、時間の範囲などの絞り込みを行いましょう。
2.時系列データから事実を把握
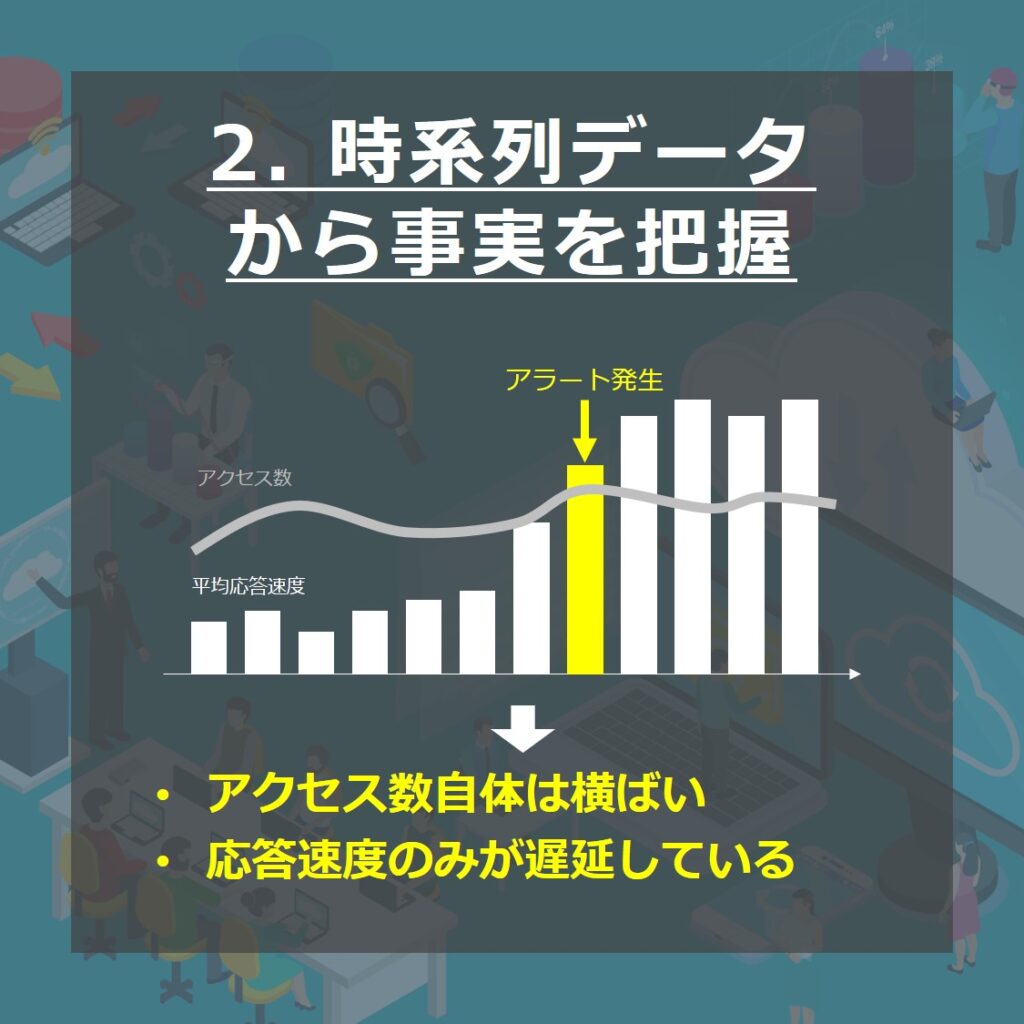
2. 時系列データから事実を把握
データを時系列に並べることで全体像が見えてきます。ある程度形になってきたら、そこから事実を把握します。
事例の内容であれば、アクセス数、平均応答速度とアラートの関係を確認できます。
まず、アクセス数についてです。
アクセス数の急増は見られません。多少右肩上がりにも見えますが、ほぼ横ばいです。
次に平均応答速度です。
アクセス数はほぼ変わらない中で、平均応答速度は急激に上昇し始めています。そして、一定値を超えたタイミングでアラート検知へと繋がっています。
3.原因を推測

3.原因を推測
アクセス数は横ばい。平均応答速度のみが遅延。という事実から原因を推測していきます。
■仮説
仮説としては、特定の処理に原因があることが考えられます。全体的に影響がありそうな場合は、処理が集中するデータベースなどが怪しそうです。特定の処理に偏っている場合は、決済サービスなどの外部サービスの影響も考えられます。
■仮説検証
「外部サービスの影響を受けている」という仮説を元に、さらにログ調査をすすめます。該当処理のみ大幅に遅延していることが確認出来たら、外部サービスベンダーへ問い合わせを行います。
■立証
ベンダーから遅延発生の言質を取れたら原因特定は成功です。
4.全体像を描く

4.全体像を描く
最後に改めて全体像を描いてみます。
原因は、外部サービスの遅延にありました。遅延の影響で自社サービスについても応答遅延が発生します。その応答遅延をアラートで検知した。という流れです。
この結果を受けて、はじめて対策を考えることが出来ます。
今回の場合は、外部サービスのベンダーと再発防止に向けての話し合いが必要です。場合によっては乗換えなどの検討が必要になります。
もし調査をせずに、インフラ増強などの対応をしても問題は解決しません。適切に調査をできる力。安定稼働のために必須の内容です。
ディーネットのAWS運用代行サービスでは

ディーネットのAWS運用代行サービスでは
ディーネットのAWS運用代行サービスでは、経験豊富なエンジニアが問題発生時の原因調査を実施しています。
障害発生時の原因特定では、適切な再発防止策がとれるように様々な観点から調査を行っています。お客様の問い合わせに対しても同様です。
AWSのみではなく、サーバー内のログについても対象範囲に含んでいるのも特徴です。多くのAWSの運用を行う事業者はサーバーの中はお客様対応となっています。扱えるデータが増えるとういことは、描ける全体像の精度が向上することを意味します。適切な原因特定ができるようになると、再発防止策の精度も上がります。
お客様が複数ベンダー間を行き来して、時間を浪費する事もなくなります。
